
How We Created a New Test Framework to Scale It For The Future

Hi there! My name is Anatoly Bobunov, and at EXANTE I work as an SDET (Software Development Engineer in Test). Over the past several years, I've been developing the test architecture for the company's backend services.
Our test framework was originally built as a unified platform for testing several backend services. As the system grew, so did the number of services, each bringing its own specific logic, client requirements, data handling and environment setup. These requirements didn't always fit within the existing architecture. As a result, local workarounds emerged: solutions that addressed specific problems while bypassing architectural constraints.
Over time, these workarounds started to accumulate. Different services used different patterns for HTTP clients, retries, data preparation and response validation. Shared abstractions gradually eroded, and the direction of dependencies became less obvious. Urgent tasks that required quick changes without a proper architectural review made the situation worse, producing temporary solutions that eventually became permanent.
The framework continued to work and covered testing scenarios, but its development was slowing down. Adding a new service required more and more exceptions, integrating new tools became increasingly difficult, and changes to core components affected unrelated parts of the system. At some point, it became clear that the current architecture had stopped scaling alongside the growing number of services.
In this article, I'll explain why we decided to build a new architectural model, what principles guided it and how we prepared the framework to work with SDKs and AI tools.
What Was Wrong with the Test Framework
To test the entire EXANTE backend, we use a monolithic repository. Since the company's founding, it has grown steadily, and our test framework has evolved with it.
At different times, different people developed different parts of the framework and introduced architectural changes. The framework's architecture didn't always evolve in a systematic or consistent way. Some changes were well thought out; others were introduced as temporary fixes intended to be rewritten or removed later. But there's nothing more permanent than a temporary solution.
After several years, we started regularly running into situations where it had become difficult or impossible to introduce improvements to the framework for the automation team. Sometimes, making a change required so much effort that it was easier to postpone it indefinitely. But technical debt wasn't the only problem. It gradually became clear that the architecture was poorly suited for further development and feature expansion. Below, I'll describe what we ran into.
Responsibilities were blurry and components were tightly coupled
In the monolithic repository, each service that the automation team tested had its own subdirectories inside tests/ and src/. At first, this didn't cause serious problems as teams mostly worked within their own tests + src pairing and rarely had to cross into other areas.
But over time, more and more cross-service tasks appeared. Changes were needed to the API layer, transport updates were required and common mechanisms for logging and tracing had to be introduced. This is where the differences in architectural approaches became highly visible:
- Code from different teams looked different.
- Layers interacted in unpredictable ways.
- In some places, business logic accessed the transport layer directly.
- In others, utility helpers bypassed abstractions.
- Configuration was being assembled in multiple places simultaneously.
The core problem wasn't any single decision but rather the absence of a clear architectural model.
- Boundaries between layers had blurred over time.
- Dependency direction was violated.
- Some parts of the code knew too much about the implementation details of other layers.
A change in one place could unexpectedly affect something else entirely. This reduced the transparency of system behaviour, complicated code reviews and slowed onboarding, ultimately impacting the speed of shipping new features.
Maintenance costs grew as technical debt accumulated
Because we kept deferring tasks due to architectural limitations or excessively labour-intensive implementation, technical debt gradually built up. Every time the architecture couldn't support a feature expansion, teams created local workarounds, such as writing their own wrappers around HTTP calls or duplicating response-handling logic. Formally, this solved specific problems, but in practice, it increased behavioural variance across the system and made it harder to evolve. It also expanded the scope of regression testing and raised the cost of changes.
The problem wasn't so much the custom implementations themselves as it was their uncontrolled proliferation. The same technical tasks (retries, status validation or error handling) were implemented differently across various parts of the codebase. This led to duplication, contract divergence and the gradual erosion of architectural boundaries. As a result, the framework became more complex, making it less predictable.
A particularly telling example was our attempt to integrate OpenTelemetry. It seemed like a standard task, but because there were several parallel branches of HTTP handling, each with different wrappers and entry points, there was simply no single extension point. The integration turned into not a refactor but a high-risk change that required touching many independent implementations.
On top of that, the test framework was used daily by the entire automation team. We couldn't simply halt development or "freeze" the framework for a few days to carry out sweeping architectural changes. This imposed additional constraints and made implementation even harder.
The architecture didn't extend well and made new tool integration difficult
Beyond the problems described above, two additional issues became apparent over time.
The first: it was difficult to integrate service SDKs into the framework. The company had begun transitioning to SDK generation for testers. However, when I tried to use them within the framework, I found that full integration would require a partial redesign of the helper layer and some test suites. There was no obvious place in the architecture to plug in such abstractions.
The second: we had started using AI-powered tools. The code was heterogeneous, unified patterns were absent and the boundaries between layers were blurry, so AI tools behaved inconsistently. They had difficulty determining which practices to treat as canonical and which architectural principles to follow when generating or modifying code. As AI coding tools become standard in engineering workflows, incoherence in the codebase directly reduces the quality of generated output.
Ultimately, we found ourselves asking more and more often: how ready is the current architecture for further growth, both of the team and of the tooling stack?
How We Built the New Test Framework Architecture
Before rewriting anything, we needed to articulate what we wanted the framework to be and what principles it should operate by. I decided to define the core architectural principles and capture them in a diagram and documentation.
We started discussing the vision within the SDET team. At first, these were informal conversations: how to separate layer responsibilities, where domain logic should end, how to centralise transport and configuration. Gradually, the first sketches of an architectural diagram emerged, along with a clearer understanding of the principles behind the new model.
The initial block diagram of the architecture looked like this:
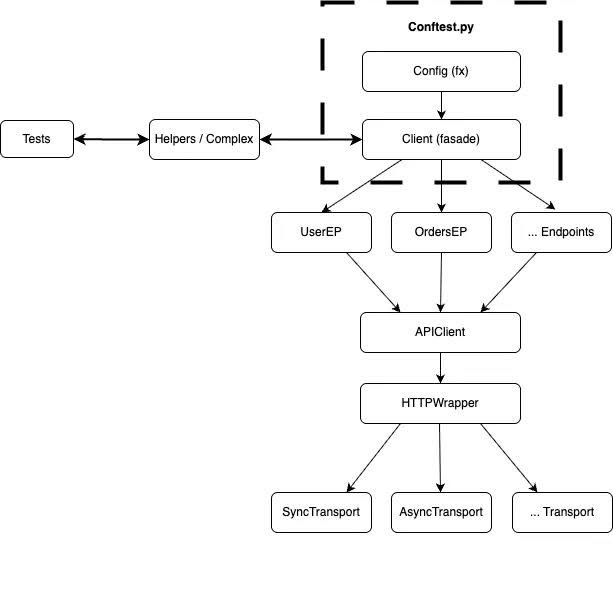
The key idea was that the framework should be:
- Simple to write and maintain tests in
- Predictable when adding new functionality
- Built with explicit layer boundaries and clear dependency direction
- Scalable as the team and number of services grow
- Ready for SDK and AI tool integration
At a certain point, my lead, Vladimir Smirnov, decided to create a new framework. I was given the time to design and implement the architecture from scratch in a separate repository. The strategy was as follows: rather than incrementally rewriting existing code inside the monorepo, we would write a new implementation and gradually migrate automated tests into the new structure.
In the new architecture, there was a sequence of clearly separated levels of responsibility. Each layer had a strictly defined area of ownership and did not cross into neighbouring layers. The core principle was directed dependencies: dependencies flowed top-down, with each level depending only on the immediately lower one.
Here is the architecture scheme we ultimately arrived at:
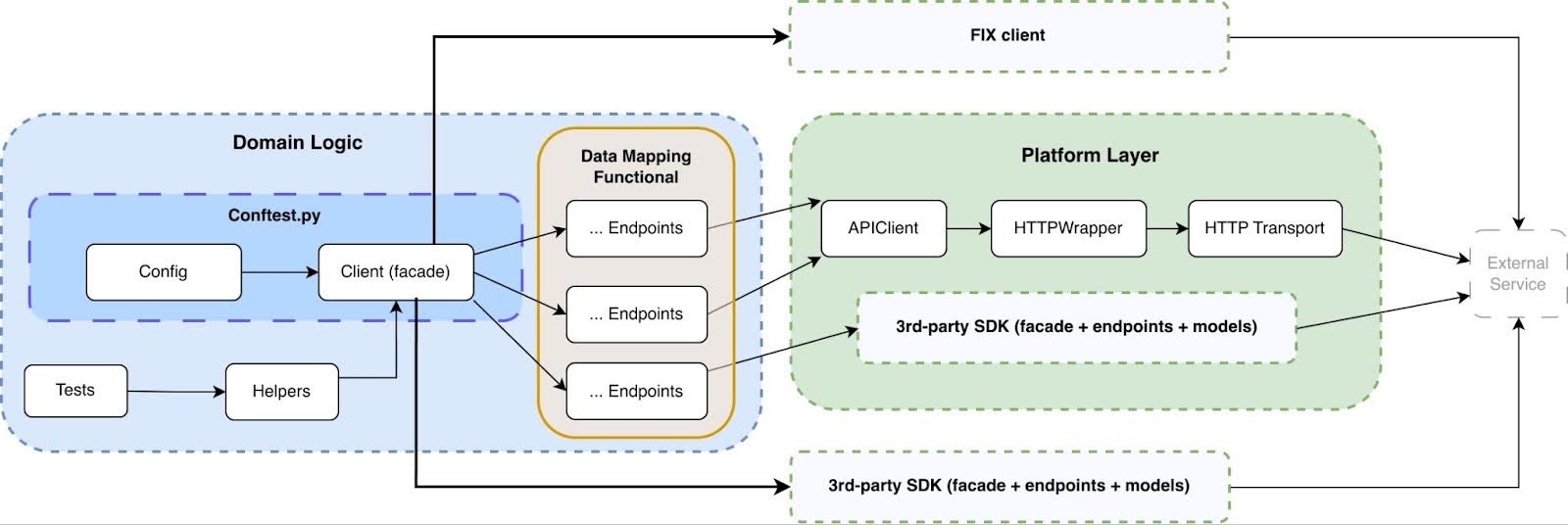
For each layer, we prepared a dedicated documentation page describing its purpose, implementation examples and constraints:
- Facade Layer: high-level API clients.
- Endpoints Layer: implementation of specific API endpoints.
- Models Layer: data structure definitions.
- Helpers Layer: reusable utilities.
- Checks helpers: business-level assertions and validations.
- Complex helpers: complex multi-step scenarios.
- Prepare helpers: data preparation for requests.
- Requests helpers: execution of API operations.
- Utils helpers: low-level utility functions.
This decomposition made it possible not only to organise the code but to formally define the responsibility of each part of the system.
The domain logic layer: where tests express business intent
The domain layer became the entry point for tests and the single place where system behaviour is described. This zone contains tests, helpers, a facade, endpoints and data models. The purpose of the domain layer is to describe system behaviour in terms of business operations, not technical details. A test should not need to know which transport is used, how an HTTP request is formed, or how headers are handled.
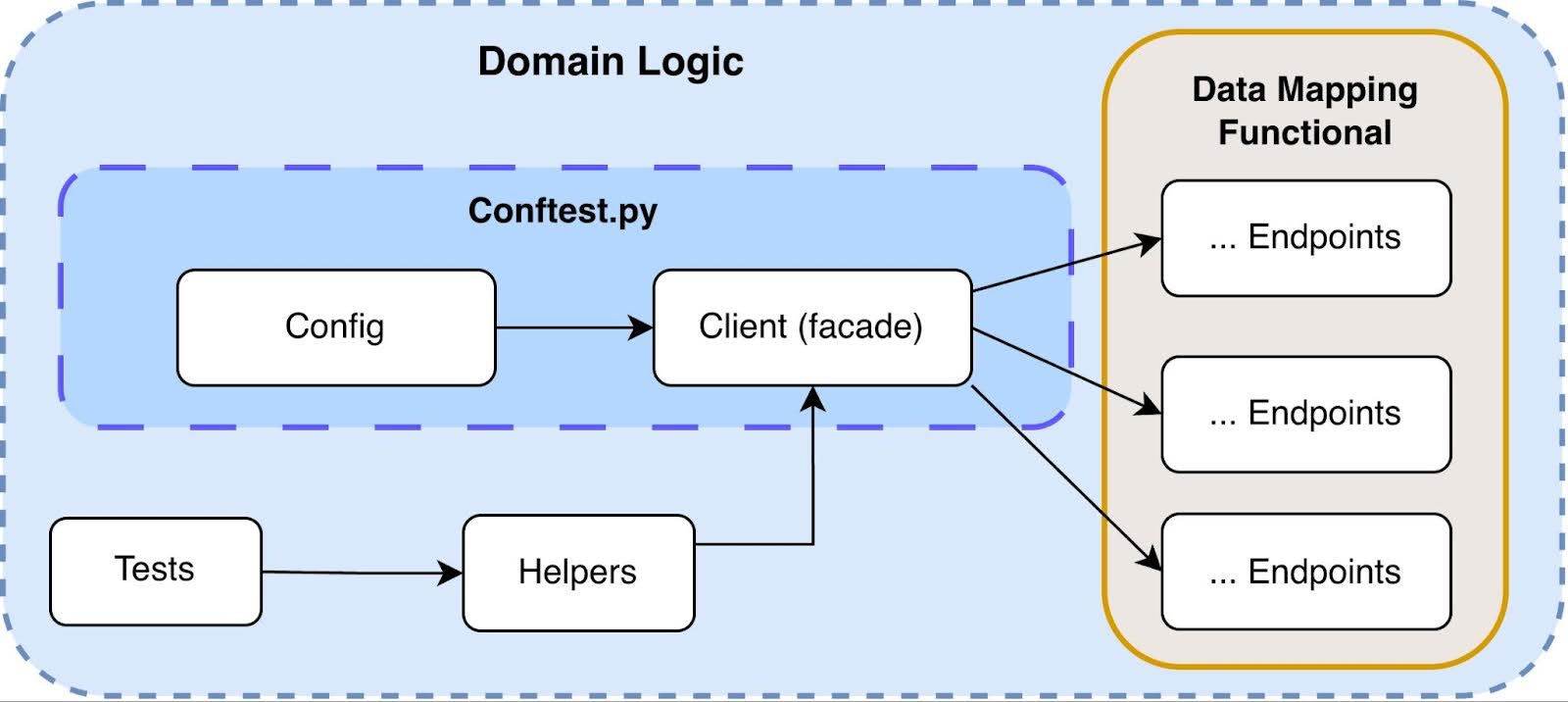
An example of the logical chain:
- The test formulates a business action.
- The Complex helper (optional) aggregates multiple steps.
- Prepare / Requests helpers prepare data and invoke operations.
- The Facade provides a high-level interface.
- Endpoints implement the specific API calls.
The Facade plays a central role. It acts as a stable contract to the service, expressed in terms of the domain model. The Endpoints layer is responsible for implementing specific API operations, including request/response mapping through models and interaction with the APIClient. It does not contain business logic or scenario coordination. The Models layer defines strict data structures (via Pydantic), providing typed request and response contracts as well as a unified serialisation and validation layer.
If the way of interacting with an API changes, tests should not need to be rewritten as changes are isolated within the facade or below. This approach made tests declarative: they describe what should happen, not how it is implemented.
In practice, this translated into the following layer structure.
Facade
The Facade is the stable entry-point contract to a service, expressed in terms of the domain model. It aggregates endpoint operations into a cohesive API and encapsulates call details, default parameters and basic checks. When the integration method with a service changes, modifications are localised within the facade and do not affect the tests.

Endpoints
Endpoints implement specific API operations: forming the request, calling the APIClient and mapping the response into domain models. This layer is responsible for the technical correctness of the integration but contains no business coordination or scenario logic. It isolates the external service's contract from the rest of the system.

Models
Models describe strict data structures using Pydantic and serve as the single source of truth for request/response schemas. They provide typing, validation and centralised serialisation. This ensures that higher layers work with predictable, validated objects rather than raw dictionaries.
Prepare helpers
Prepare helpers are used to generate valid payloads, default configurations, and test entity setup. They reduce duplication and ensure parameter consistency across tests. Their focus is on correctly establishing the state before an operation is executed.
Requests helpers
Requests helpers encapsulate recurring patterns of facade or endpoint calls. They can add standard parameters, wrap calls with additional checks, or handle typical scenarios. This reduces test coupling and keeps tests more compact.

Complex helpers
Complex helpers aggregate multiple domain operations into a single scenario step. They coordinate a sequence of actions while preserving business meaning at a high level. This layer is used when a scenario repeats across multiple tests and requires an atomic logical abstraction.
Utils (within the domain layer)
Utils contain helper functions that are not directly tied to transport or infrastructure, but simplify working with domain objects. These might be transformations, invariant checks, or comparison utilities. Their use is confined to the domain area to avoid blurring architectural boundaries.
The platform layer: hiding infrastructure complexity
The platform layer is responsible for the technical details of interacting with external services, covering everything that tests and domain logic should never need to think about. It includes: API Client, HTTP Wrapper, HTTP Transport, external SDK integrations and centralised configuration.
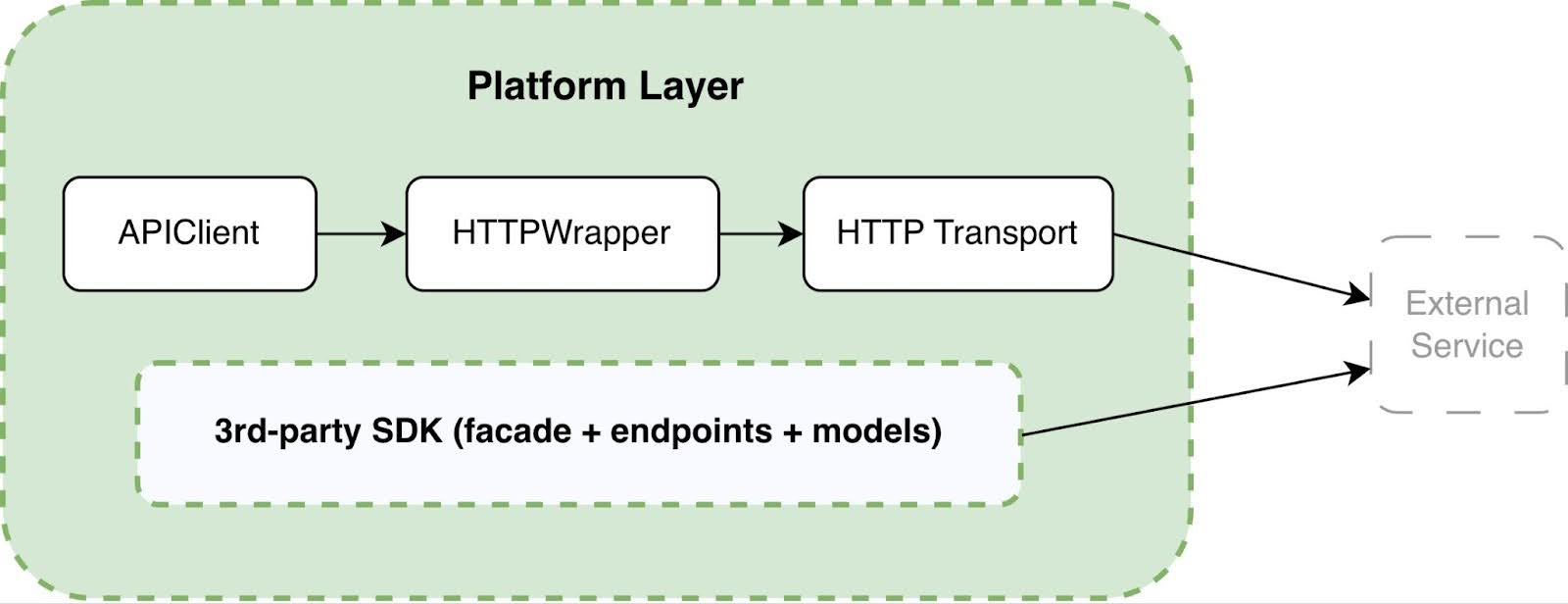
The purpose of this level is to fully isolate infrastructure complexity:
- HTTP client (httpx)
- Header handling
- Retries
- Timeouts
- Logging
- Tracing
- Error handling
API Client
The API Client is an adapter between the domain model and the transport layer. It provides Endpoints with a stable, predictable contract for executing operations and hides the details of forming HTTP calls and configuring the client. This layer centralises base URL management, authorisation and shared request parameters so that upper layers don't depend on the specific transport implementation.
HTTP Wrapper
The HTTP Wrapper encapsulates recurring infrastructure logic around a request. It concentrates on retries, timeouts, basic logging, error handling and other cross-cutting mechanisms. As a result, the behaviour of network interaction is standardised and not duplicated at each endpoint.
HTTP Transport
HTTP Transport is responsible exclusively for sending a request and receiving a response. It contains no business logic and coordinates no scenarios, as its responsibility is limited strictly to low-level interaction with the HTTP client (e.g., httpx). This separation makes the transport replaceable and prevents changes from affecting other levels.
This separation provided us with the control and behavioural transparency that had previously been missing. We gained a single extension point, for example, to connect OpenTelemetry, the ability to introduce middleware without cascading changes in domain logic and a clear mechanism for integrating 3rd-party SDKs without touching the test layer.
As a result, the platform layer stopped "leaking" upward. It became an isolated, manageable and, when necessary, replaceable component. We can now swap out the transport or add middleware without cascading changes across the entire project. Architecture requires discipline and code review to prevent layers from blending together again.
SDK and External Client Integration
Special attention should be paid to integrating 3rd-party SDKs and specialised clients, including FIX clients.
In the new architecture, we began treating SDKs as an alternative implementation of the external service interaction layer. They can either be plugged in through the platform layer or used directly in a strictly limited context. This allowed us to gradually transition to auto-generated SDKs, avoid rewriting automated tests and, where possible, eliminate duplicated logic.
As a result, the new architecture ceased to be a collection of historically accumulated decisions. It became a formal model with defined rules for dependencies and extension. That is precisely what enabled us to move forward by initiating test migration and the gradual decommissioning of the old framework.
Key Capabilities of the New Framework
At the time of writing, we are gradually migrating from the old framework to the new one and actively introducing AI to automate test writing. It is too early to discuss quantitative results as some tests are still running in the old architecture. Nevertheless, even at the design stage and during the first migrations, it became clear that the new architecture simplified SDK integration, made AI tool behaviour more predictable through well-defined layer boundaries, and made it possible to add new functionality without touching unrelated parts of the framework. I made a point of preserving the familiar model for writing automated tests so that the transition for the team would feel evolutionary rather than abrupt.
Formalising domain steps
The process of writing automated tests is increasingly becoming an exercise in describing test scenarios. As the team works, they gradually accumulate more specialised functions (helpers or steps) that are then reused in other tests. This is the natural evolution of any mature test suite: a tester writes a specific scenario, a repeating fragment appears within it, they extract it into a separate function, and step by step, they build a library of domain operations.
We had always tried to follow this kind of approach: extracting repeated code, aggregating logic and encapsulating steps. But now we have gone further and formalised the process:
- We defined criteria for what qualifies as a step, where it should live, which layer it should depend on, and which contracts it should respect.
- We established requirements for naming, the level of abstraction, and the boundaries of responsibility.
In other words, we turned a spontaneously evolving practice into a governed architectural mechanism. As a result, reuse became not just convenient, but predictable. And the step library became not a collection of random utilities, but a deliberate layer embedded within the framework's overall architecture.
A minimal test example can be seen below:

Declarative validation via the custom @response_mapping decorator
If the previous section addressed the scenario level, this next framework mechanism implements contract formalisation through declarative HTTP response validation.
In the old approach, HTTP status checks had no fixed layer of ownership. Most often, they appeared in helper functions, but over time, they started showing up in the tests themselves and at the API request level as well. Formally, these checks solved the same problem but were implemented differently. As a result, validation logic gradually duplicated and started "spreading" across the architecture.
The volume of these checks grew, their behaviour became less predictable, and maintaining them became harder. Moreover, in different places, the same status codes were interpreted differently, which effectively eroded the API contract. When reviewing code, I regularly encountered identical checks scattered across different layers.
So I decided to move contract validation to the Endpoints layer and formalise it through a decorator.
In the new approach, validation happens at the Endpoints layer. A @response_mapping decorator is added to each method of an Endpoint class, taking as arguments a set of positive and negative status codes along with data models for those responses. Status codes and data models are sourced from the service's Swagger specification.

The decorator automatically:
- Maps the status code to the corresponding model
- Validates the response body through Pydantic
- Raises an exception on an unexpected status code
In this way, the API contract is no longer a scattered check buried in tests but rather part of the client's architecture. This reduces the likelihood of discrepancies and simplifies integration maintenance.
A unified fixture pattern
All client fixtures in the new framework live in the fixtures/ directory and follow a single template. Within that directory, I introduced a split between public and private clients. In the conftest.py file, we simply register the fixture set as a plugin: pytest_plugins = ("fixtures.clients",).
This standardisation seems like a minor detail until you go through onboarding with a new engineer. A single entry point and a clear understanding of where clients come from and how they're created make a significant difference in understanding how tests run.
Inside the fixture, a facade client is created, configuration is encapsulated and lifecycle management is handled.
A typical pattern example:

Consistent structure simplifies writing and reviewing service code. Consistency reduces cognitive load. And that directly affects development speed. The predictability present at the level of scenarios and contracts carries through to the infrastructure level as well.
AI and auto-generation
I thought carefully in advance about how the new architecture would interact with AI tools.
Currently, we use a three-tier documentation system in the repository:
- Readme.md Contains foundational knowledge about the project: what it is, how to install and configure it locally, how to run tests, and what lives in which folder.
- docs/ folder The Markdown files here contain deeper information on how to write tests, various tips for running tests during debugging, and other details. This is a slightly deeper layer that a user might occasionally need.
- docs/detailed/ subfolder Used as a structured knowledge source for Claude Code. Markdown files in docs/detailed/ contain detailed information about the architecture, patterns, and code examples for each layer in the framework. This layer is rarely needed by testers or developers in day-to-day work, but it's convenient to reference when working with AI.
The Claude.md file acts as a set of constraints for Claude Code. It specifies which principles to follow when writing code, which documentation files to consult and when, custom rules to apply in different scenarios, and similar guidance.
Now, when an engineer uses an AI tool, they can easily provide the right context simply by sending a link to the relevant documentation. When the architecture is formalised and documented, AI begins to work significantly better. Comprehensive, well-structured documentation has a noticeable impact on the quality of generated code, code reviews and AI-driven suggestions about the codebase. In a large monorepo, this starts to matter just as much as the quality of the architecture itself.
Conclusion
We built the new architecture as a stable foundation for the framework's continued development.
We are currently refining, discussing internally, and gradually formalising several areas:
First, creating a set of specialised exceptions. It's important to us that an error clearly reflects the level at which it occurred: transport, contract or domain scenario. This simplifies diagnostics, speeds up code reviews and makes system behaviour more transparent.
Second, third-party SDK integration. We are establishing a unified process for connecting them and documenting it. Our goal is for an engineer to add a new client or auto-generated SDK following a clear architectural pattern, rather than implementing it differently each time.
Third, we want to extract the platform layer into a separate repository and publish it as a Python library, or possibly several libraries. This would isolate the infrastructure component from the test layer, enabling its reuse across other projects while maintaining unified integration standards.
In parallel, test migration is continuing. We have already started moving two services into the new architecture. I continue to gather feedback, refine the documentation and adjust the architecture as we use it. This helps stabilise the implementation and validate architectural decisions in practice.
An architecture only comes to life when people actually use it. The new model has simplified adding functionality, made SDK integration predictable, and reduced coupling between components. But the key factor for us has been active AI use: clear layer boundaries, unified patterns and formalised contracts enable AI tools to generate automated tests more reliably and modify existing code. This speeds up test writing, lowers the cost of changes and makes the evolution of our automation more sustainable.
本文提供給您僅供資訊參考之用,不應被視為認購或銷售此處提及任何投資或相關服務的優惠招攬或遊說。金融商品交易涉及重大損失風險,可能不適合所有投資者。過往績效不代表未來表現。







由專業人士建立。為專業人士打造。
